Running BERT without Padding. Contribute to bytedance/effective_transformer development by creating an account on GitHub.
2211.05102] 1 Introduction

PDF) Packing: Towards 2x NLP BERT Acceleration

GitHub - rickyHong/Google-BERT-repl

Tokenizing in the dataset and padding manually using tokenizer.pad in the collator · Issue #12307 · huggingface/transformers · GitHub

Embedding index getting out of range while running camemebert model · Issue #4153 · huggingface/transformers · GitHub

Bert base chinese model gives error :- EagerTensor object has no attribute 'size' · Issue #7406 · huggingface/transformers · GitHub

Using a Model without any pretrained data · Issue #2649 · huggingface/transformers · GitHub

BertForSequenceClassification.from_pretrained · Issue #22 · jessevig/bertviz · GitHub

Tokenizers can not pad tensorized inputs · Issue #15447 · huggingface/transformers · GitHub

process stuck at LineByLineTextDataset. training not starting · Issue #5944 · huggingface/transformers · GitHub

BART finetune.py: model not learning anything · Issue #5271 · huggingface/transformers · GitHub

Full-Stack Optimizing Transformer Inference on ARM Many-Core CPU
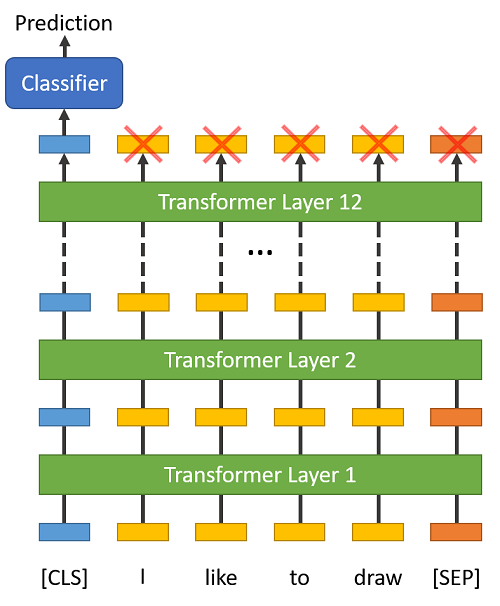
BERT Fine-Tuning Sentence Classification v2.ipynb - Colaboratory

CS-Notes/Notes/Output/nvidia.md at master · huangrt01/CS-Notes · GitHub

Lab 6: BERT