The LLM Triad: Tune, Prompt, Reward - Gradient Flow
$ 29.00
4.5(583)In stock
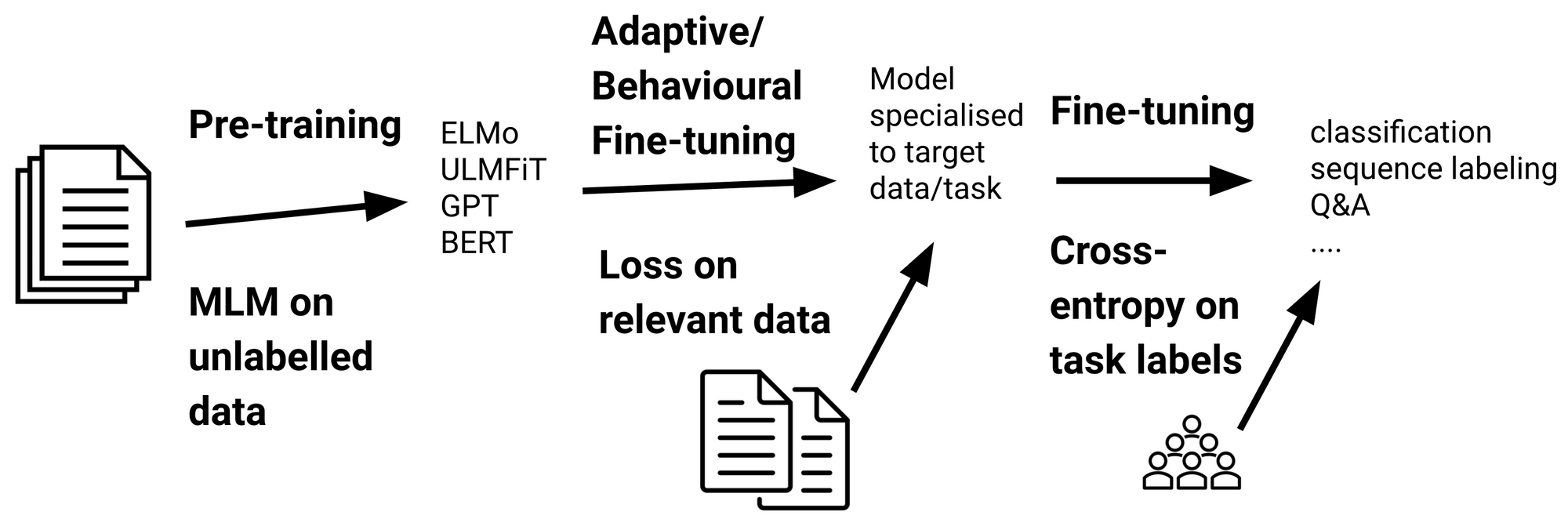
As language models become increasingly common, it becomes crucial to employ a broad set of strategies and tools in order to fully unlock their potential. Foremost among these strategies is prompt engineering, which involves the careful selection and arrangement of words within a prompt or query in order to guide the model towards producing theContinue reading "The LLM Triad: Tune, Prompt, Reward"
Some Core Principles of Large Language Model (LLM) Tuning, by Subrata Goswami
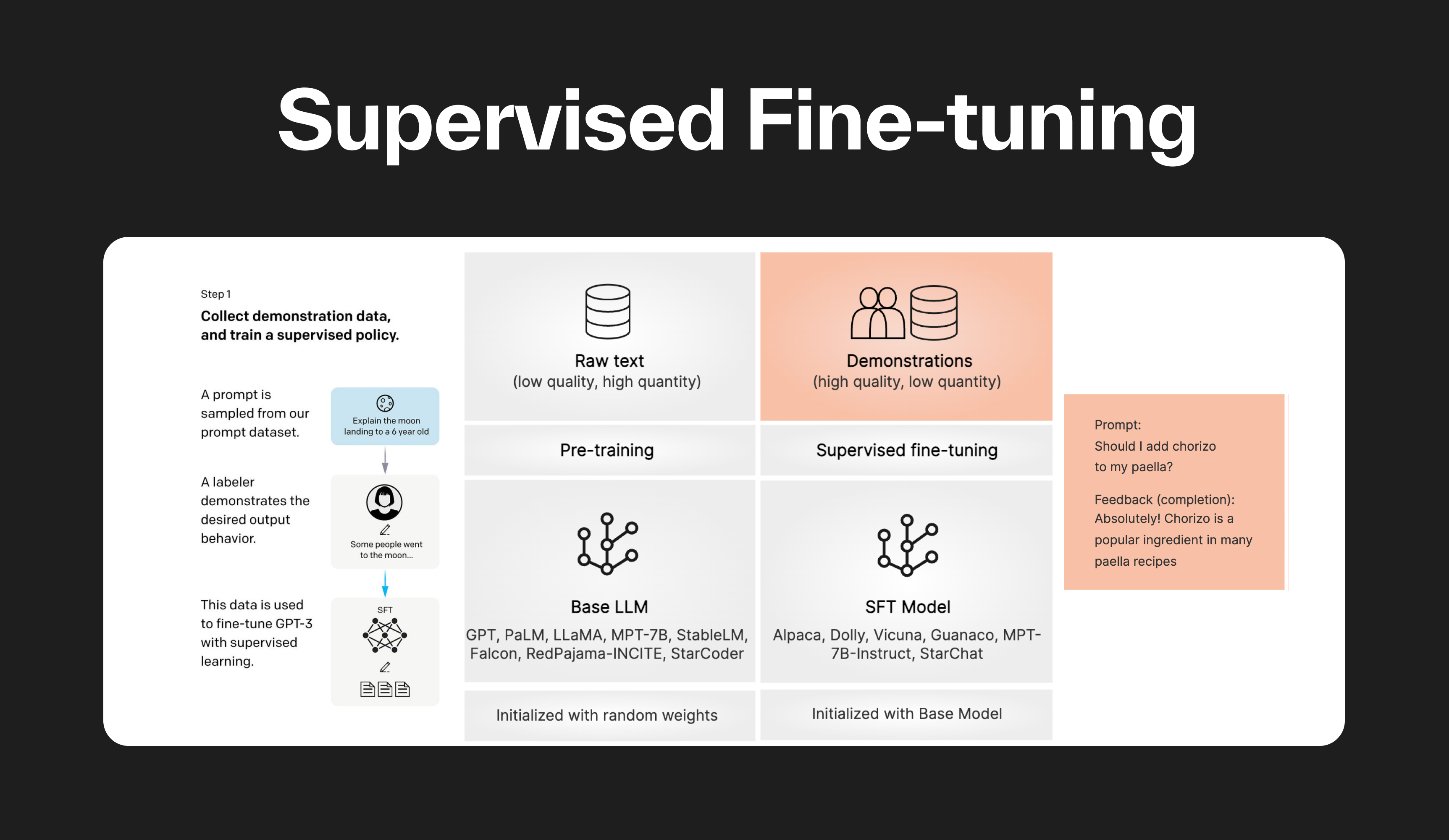
Understanding RLHF for LLMs
Gradient Flow
Gradient Flow
Beyond Training Objectives: Interpreting Reward Model Divergence in Large Language Models
HOW TO USE RLHF TO FINE-TUNE YOUR DATA ON GOOGLE CLOUD PLATFORM USING LLAMA-2, by Nnaemeka Nwankwo
A Comprehensive Guide to fine-tuning LLMs using RLHF (Part-1)
A Comprehensive Guide to fine-tuning LLMs using RLHF (Part-1)
LLM Studies (Part 4) – Reinforcement Learning from Human Feedback (RLHF) – Sherman Wong
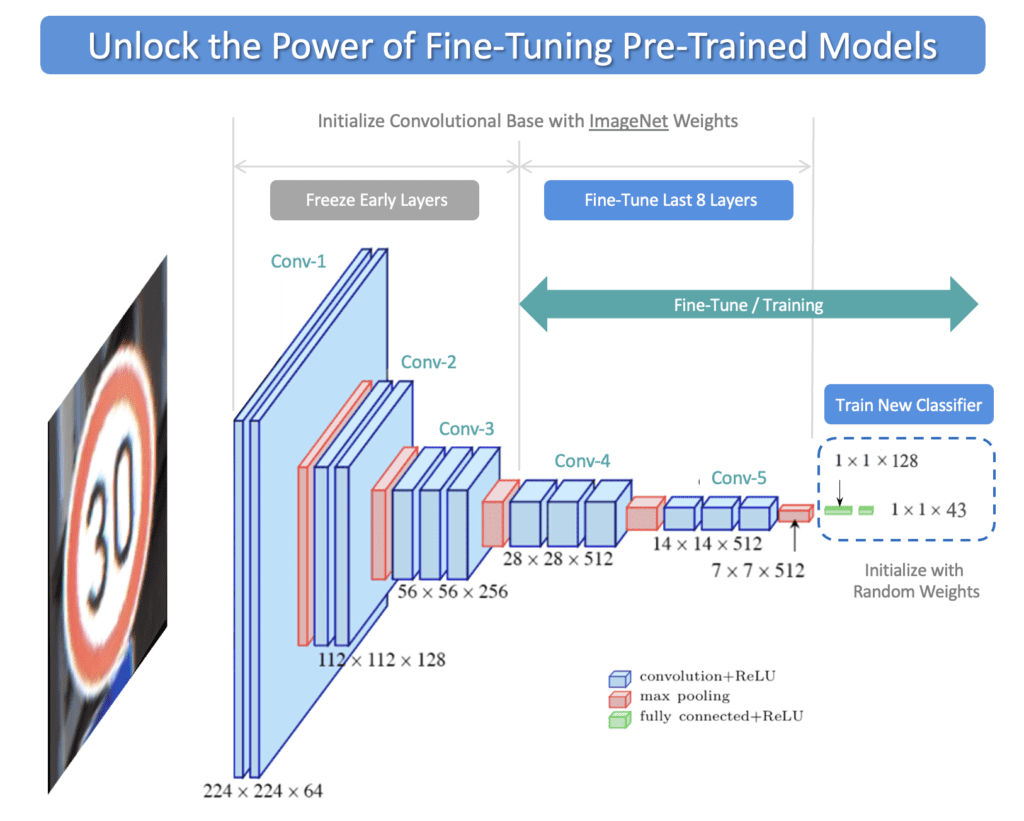
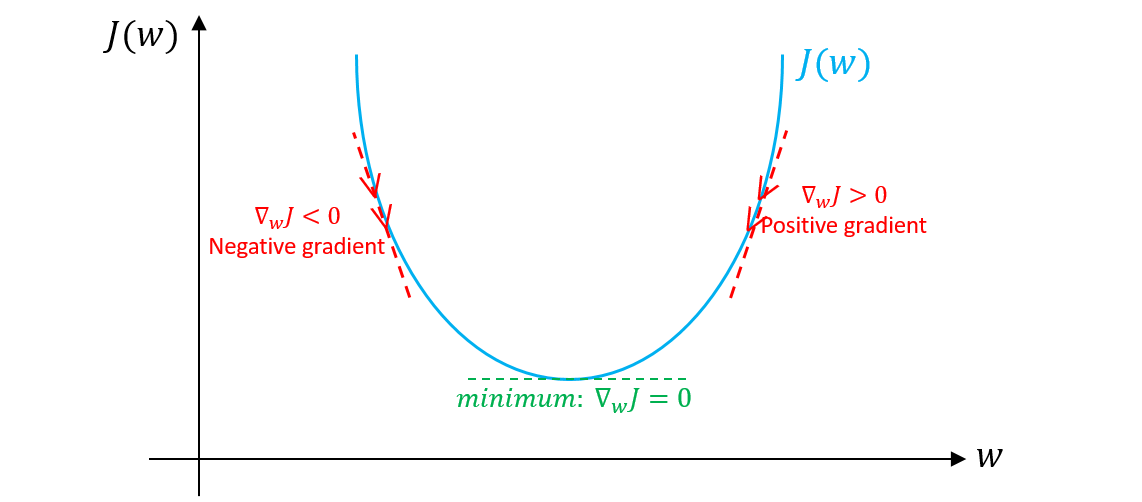
Damien Benveniste, PhD on LinkedIn: Fine-tuning an LLM may not be as trivial as we may think! Depending on…






.png)
.png)